Map
HashMap
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK1.8 之前
“拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8 之后
当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
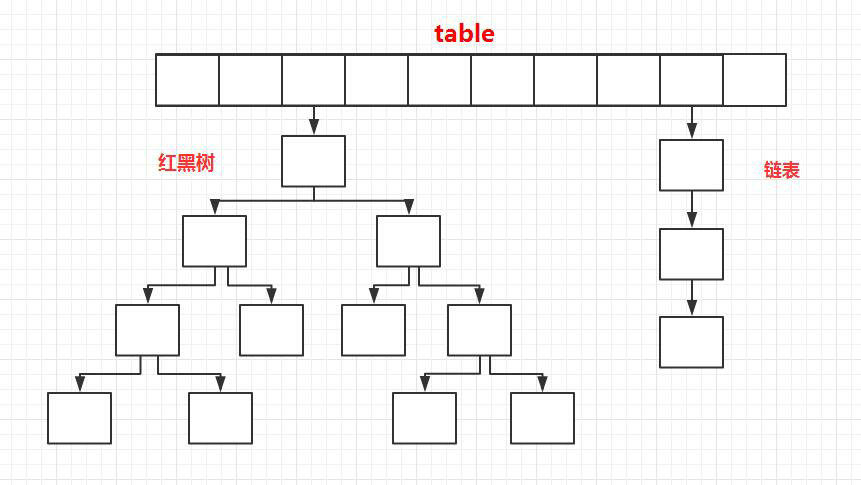
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
ConcurrentHashMap
1.8及之后
- 用table保存数据,锁的粒度更小,减少并发冲突的概率。采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率,并发控制使用Synchronized和CAS来操作。
- 存储数据时采用了数组+ 链表+红黑树的形式。
- CurrentHashMap重要参数:
1 | private static final int MAXIMUM_CAPACITY = 1 << 30; // 数组的最大值 |
- 扩容机制
- nextTable: 扩容期间,将元素迁移到 nextTable 新Map, nextTable是共享变量。
- sizeCtl: 多线程之间,sizeCtl来判断ConcurrentHashMap当前所处的状态。
- 通过CAS设置sizeCtl属性,告知其他线程ConcurrentHashMap的状态变更。
- transferIndex: 扩容索引,表示已经完成数据分配的table数组索引位置。
- 数据转移已经到了哪个位置? 其他线程根据这个值帮助扩容从这个索引位置继续转移数据
- ForwardingNode节点: 标记作用,表示此节点已经扩容完毕,hash值等于-1
- 数组位置的数据已经被转移到新Map中,此位置就会被设置为这个属性
- 这个属性包装了新Map,可以用find方法取扩容转移后的值
扩容流程:
- 线程执行put操作,发现容量已经达到扩容阈值,需要进行扩容操作
- 扩容线程A 以CAS机制修改
transferindex值,然后按照降序迁移数据,transferindex是数组尾部的索引transferindex的初始值: 新数组的长度 - 1 -> 就是数组的最后一位
- 迁移hash桶时,会将桶内的链表或者红黑树,按照一定算法,拆分成2份,将其插入
nextTable[i]和nextTable[i+n](n是之前table数组的长度)。- 扩容后重新计算的hash值与之前hash值一样,则存放位置不变
- 重新计算的hash值与之前hash值不一样,则存放再索引i +n处(之前的数组长度 + 计算的索引)
- 迁移完毕的hash桶,都会被设置成
ForwardingNode节点,以此告知访问此桶的其他线程,此节点已经迁移完毕,但数据并没有全部迁移完成。 - 此时线程2访问到了
ForwardingNode节点,如果线程2执行的put或remove等写操作,那么就会先帮其扩容。- 如果线程2执行的是get等读方法,则会调用
ForwardingNode的find方法,去nextTable里面查找相关元素。
- 如果线程2执行的是get等读方法,则会调用
- put
put操作采用 CAS + synchronized 实现并发插入或更新操作
1 | // Node 节点的 hash值在HashMap中存储的就是hash值,在currenthashmap中可能有多种情况哦! |
涉及到重要函数initTable、tabAt、casTabAt、helpTransfer、putTreeVal、treeifyBin、addCount函数。
- initTable
「只允许一个线程」 对表进行初始化,如果不巧有其他线程进来了,那么会让其他线程交出 CPU 等待下次系统调度Thread.yield。这样,保证了表同时只会被一个线程初始化,对于table的大小,会根据sizeCtl的值进行设置,如果没有设置szieCtl的值,那么默认生成的table大小为16,否则,会根据sizeCtl的大小设置table大小。
1 | // 容器初始化 操作 |